¶ Response Selectors in PeepPavlov Dream
The response selection process in PeepPavlov Dream involves the coordination of the Skill Selector and Response Selector components within the DeepPavlov Agent framework.
The Skill Selector determines the list of skills to generate response candidates for the current context, while the Response Selector is responsible for selecting the final response. Together, they create the process of dialog management.
¶ Dialog Management Schema
The generalized approaches to dialogue management are described in the figure below.
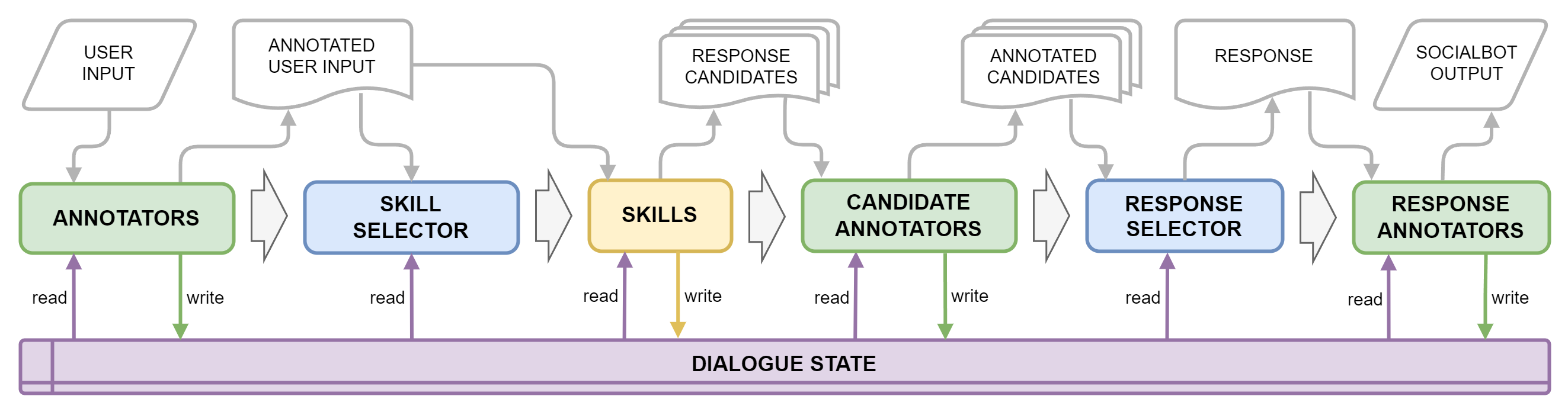
The Response Selector service returns the selected skill’s name, the response text (which can be overwritten), and the confidence level:
{
"skill_name": "chitchat",
"text": "Hello, Joe!",
"confidence": 0.3
}
Additionally, the Response Selector can overwrite human or bot attributes as needed:
{
"skill_name": "chitchat",
"text": "Hello, Joe!",
"confidence": 0.3,
"human_attributes": {
"name": "Kate"
}
}
¶ Response Selector Approaches
¶ Confidence-based Bot Responses
In a modular dialog system, each skill returns a response candidate along with a confidence value ranging from 0 to 1, where 1 represents the highest level of confidence. To select the appropriate response, an algorithm based on confidence maximization is employed. However, this approach faces challenges such as equal confidence values for multiple candidates and differing confidence value distributions across skills.
To address these challenges, the Dream Response Selector incorporates an empirical formula that combines the skill confidence and the evaluation of the response candidate. The evaluation is performed by the CoBot Conversation Evaluation model, considering factors such as:
- topic correspondence
- interestingness
- user engagement
- response comprehensiveness
- correctness
The Response Selector filters out “bad” response candidates, avoids repeated sentences in the dialog, and calculates a final score based on confidence and evaluation predictions. Multiple response candidates can be combined, and linking questions or transitions to scripted skills can be added to ensure smooth conversation flow.
¶ Tag-based Response Selector
In DeepPavlov Dream, various skills are combined, including template-based, retrieval, and generative skills. To enable a seamless integration of skills with different origins, the Response Selector incorporates a tag-based approach.
Each response candidate is assigned two additional tags: the continuation flag and response parts. These tags are provided by the skill proposing the response. The continuation flag indicates whether the conversation can continue after the candidate response, and the response parts specify the presence of acknowledgment, body, and prompt in the response.
¶ The Selection process explained
Firstly, the selection algorithm checks for the special user intents that a special component can immediately respond to.
If the user wants to switch or request a particular topic, priority is given to candidates with prompts.
Finally, if the user’s dialogue act requires some action by the bot (for example, if a user requests an opinion, an expression of opinion is expected from the bot), priority is given to response candidates containing the required dialogue acts.
In other cases, the algorithm uses the following priorities:
-
(1) candidate response by a scripted skill with which a dialogue is in progress;
-
(2) script-part candidate responses containing entities (not necessarily named entities) from the last user’s utterance;
-
(3) one-step candidate responses containing entities from the last user’s utterance;
-
(4) other script-part candidate responses;
-
(5) other one-step candidate responses.
Script-part candidate responses are those from scripted skills which will be able to continue the script if the current candidate will be returned to the user.
One-step candidate responses are not a part of the script or the last utterance in the script.
¶ Developing Your Own Response Selector
You can develop your own rule-based Response Selector using the provided code as a foundation. The code enables response selection based on the confidence and text of response candidates.
#!/usr/bin/env python
import logging
import numpy as np
import time
from flask import Flask, request, jsonify
from os import getenv
import sentry_sdk
logging.basicConfig(format="%(asctime)s - %(name)s - %(levelname)s - %(message)s", level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
@app.route("/respond", methods=["POST"])
def respond():
st_time = time.time()
dialogs = request.json["dialogs"]
response_candidates = [dialog["utterances"][-1]["hypotheses"] for dialog in dialogs]
selected_skill_names = []
selected_responses = []
selected_confidences = []
for i, dialog in enumerate(dialogs):
confidences = []
responses = []
skill_names = []
for skill_data in response_candidates[i]:
if skill_data["text"] and skill_data["confidence"]:
logger.info(f"Skill {skill_data['skill_name']} returned non-empty hypothesis with non-zero confidence.")
confidences += [skill_data["confidence"]]
responses += [skill_data["text"]]
skill_names += [skill_data["skill_name"]]
best_id = np.argmax(confidences)
selected_skill_names.append(skill_names[best_id])
selected_responses.append(responses[best_id])
selected_confidences.append(confidences[best_id])
total_time = time.time() - st_time
logger.info(f"rule_based_response_selector exec time = {total_time:.3f}s")
return jsonify(list(zip(selected_skill_names, selected_responses, selected_confidences)))
if __name__ == "__main__":
app.run(debug=False, host="0.0.0.0", port=3000)
¶ Registering Your Own Response Selector
Note that you must register a response selector before you can test it with your own copy of Dream distribution.
To register your Response Selector, add its configuration to the docker-compose.yml located in the root directory, and to pipeline_conf.json located in the /agent subdirectory of the repository.
After adding new skill, it should be built and run using docker-compose -f docker-compose.yml up --build _response_selector_name_, followed by building and running agent by running command docker-compose -f docker-compose.yml build agent followed by docker-compose -f docker-compose.yml up agent.
For more details, please refer to the Response Selector documentation in the DeepPavlov Agent documentation.