¶ What Is DeepPavlov Agent?
DeepPavlov Agent is a free, open-source framework for development of scalable and production ready multi-skill virtual assistants, complex dialogue systems, and chatbots.
¶ Documentation
- DeepPavlov Agent Documentation Docs @ ReadTheDoc
¶ High-Level Architecture
¶ Source Code
- Source Code Agent @ GitHub
¶ Resources
- DeepPavlov Agent Agent @ DeepPavlov.ai
¶ Why we use DeepPavlov Agent
The text is from the article on Medium
A dialogue system usually contains a natural language understanding (NLU) module which may include several neural networks and knowledge graphs (KGs) retrieval models. Let us introduce dp-agent terminology straight away and call NLU components of the dialogue system “Annotators”. Besides, a dialogue system also includes some response generation components (call them “Skills”) which could be simple rule-based algorithms using information from Annotators, neural retrieval, or generative models which potentially consume a lot of inference time and computational resources. Furthermore, some neural models do not require anything but a current user utterance and dialogue context containing several previous utterances. However, it should be noted that one of the most popular generation approaches in “Alexa Prize Challenge 4” was knowledge-grounded response generation. It implies not only a current utterance and dialogue context but also a knowledge paragraph as an input for the neural model. Such information could be obtained in Annotators using knowledge retrieval methods. Therefore, knowledge extraction and response generation became consistent procedures.
The difficulties described above bring to the necessity of the orchestration system which will take into account component dependencies on each other and run them in the corresponding order. Components requests are going to be asynchronous, and the system should be able to gather and store this information correctly.
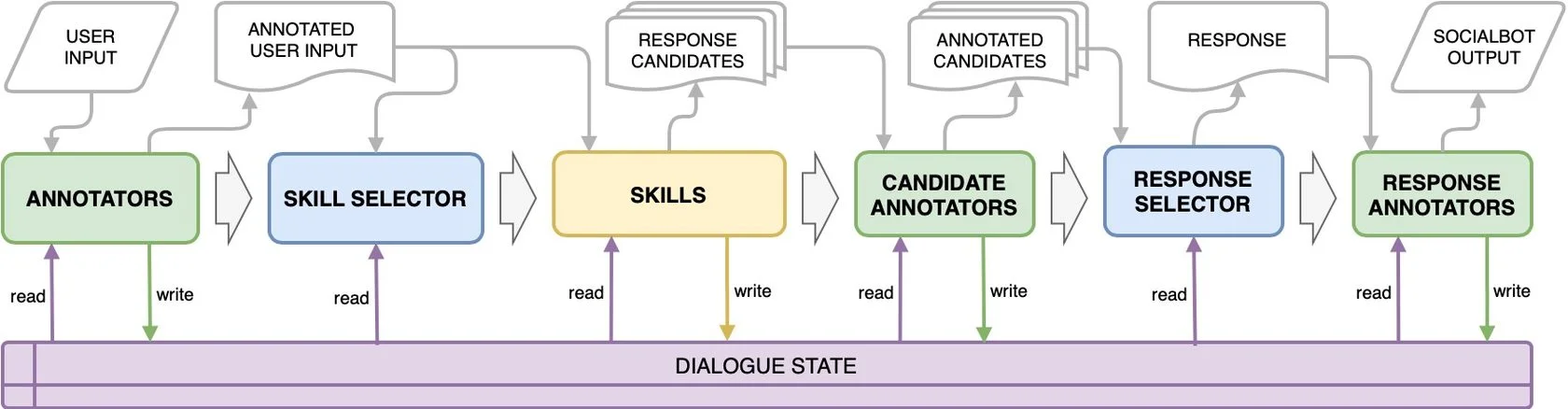
The DREAM dialogue system is built upon the dp-agent library. It is an open-source library for building complex dialogue systems and chat-bots. The main pipeline of the dp-agent is represented in the picture below. There are main component groups: Annotators, Skills, Candidate Annotators, Response Annotators, and two main dialogue management components — Skill Selector and Response Selector. The Dialogue State is a shared memory that contains all the information about the dialogue because dp-agent implies stateless components (they do not store information about particular dialogues). There are only two synchronization points — Skill Selector and Response Selector. All components in other groups could be run in parallel, and the agent allows to indicate which services are required by each other in the configuration file.
The dp-agent pipeline is asynchronous, i.e. one user’s request does not block the agent, and does not prevent the agent from receiving and processing requests from other users. For example, there are three components A, B, and C, and the output of service A is required to make a request to B and C. So, the agent sends a request to service A, and after receiving the result from service A it sends requests to components B and C.If at this moment the agent receives a new request from another user, then the agent sends the request to service A, despite the fact that it did not receive a response from B and C for the first user. By the way, for components that are not crucial within the pipeline, one may set a timeout for waiting for a response from them in order to reduce the agent response time.
Each service is deployed in a separate docker container. In addition, separate containers are used for the agent itself and the database (the latter — in the case of running the bot locally). For development one can run the dialogue system locally using docker-compose, when using in production we utilize Kubernetes. Since the DREAM dialogue system now requires a lot of computational resources, we deployed it on our server and made it available for developers using proxy. So, developers usually run locally only an agent container, a database, and modified services of interest. All other containers are replaced with small ones containing nginx that sends requests to the system on our servers.
The DREAM dialogue system was running on Amazon resources during the challenges handled 7 TPS (transactions per second) for 1 minute. The average response time was about 3.5–4 seconds. The main disadvantages of the DREAM deployment were the utilization of relatively slow MongoDB for dialogue state storage and a set of tools for monitoring and load optimization which required further improvement. Moreover, we want to include large neural models for response generation whose inference time is big but they utilize only the current utterance and dialogue context, so they could be requested in parallel with Annotators and Skills.