¶ Reference Materials
This page is a great start for those who want to understand how the entire Dream and its separate components function. We prepared several articles about each of the components and how they are managed.
¶ Main features of Dream
-
The list of available LLMs. Dream focuses on LLMs in production. We support different LLMs: HuggingFace transformers, OpenAI API, Anthropic API. One may choose any of the models from these sources. Some of these models are up and running on our servers and can be used for free as a proxy (see Proxy), while others are accessed via API and have to be paid for separately according to the providers’ rates. If you have enough resources, you may also use any other model from HuggingFace in Dream. However, you will have to run it locally.
-
Custom Knowledge Graphs. Dream provides an option of using custom KGs for response generation. That is useful if you want to extract information about the user and/or chatbot from their utterances and store it to use later in the conversation. Custom knowledge graphs may, for example, help you make your chatbot’s responses more consistent throughout the entire interaction.
-
Optimized computation time. Dream uses a backbone Multitask classification model for user input annotation, thus reducing overall computation time.
¶ Dream Distributions
-
Dream Distributions. Distribution is a set of configuration files that define which components are used in this particular assistant, this define an assistant itself. For example, different Dream distributions may use different Annotators and Response Selectors, feature entirely rule-based, generative or mixed Skills, and even speak different languages.
-
You can create your own distribution with ready-made or customized components or use an existing one (see Provided Guides).
-
For an instruction on how to run an existing distribution, see this How-to-Start tutorial.
-
Utilize dreamtools CLI package to accelerate distributions creation process.
¶ Dream Components
As an introduction to the complex architecture of Dream, take a look at this figure demonstrating what steps the user input has to undergo for the chatbot to produce its response. All elements of the pipeline are running asynchronously with two points of synchronization: Skill Selector and Response Selector.
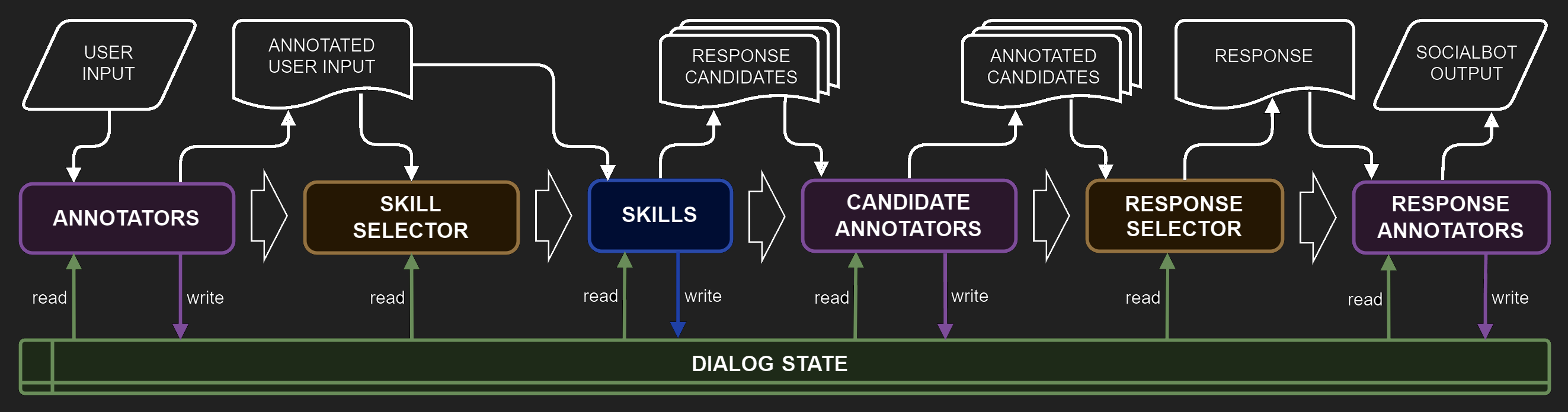
The dialog system consists of the following:
-
Annotators preprocess the user input performing various natural language understanding tasks. Annotators may also retrieve contextual information from external sources such as Wikipedia or news.
-
Skill Selector picks a subset of Skills based on some pre-defined conditions and the results of annotation.
-
Skills that were chosen on the previous step return one or several response candidates each, based on the previous context and the annotations.
-
Candidate Annotators annotate the response candidates with the use of natural language understanding methods.
-
Response Selector picks the best response candidate.
-
Response Annotators annotate the final response candidate selected on the previous step with the use of natural language understanding methods.
-
Dialog State contains the whole dialog description including all utterances and their annotations, hypotheses and their annotations, user and bot attributes. If needed, different services may communicate via shared memory stored in the Dialog State.
List of components available in Dream contains short descriptions and requirements ot most of the avilable components. One may also find README files for some components in the corresponding folders.
¶ Developer Materials
If you want to understand the inner workings of Dream even better, you may read more about the following mechanisms:
-
dreamtools CLI package to accelerate distributions creation process.
-
Connectors define whether the component is a part of the Agent container (python connector) or a separate docker container (http connector). Most essential and light-weight components are python containers.
-
Formatters reformat dialog data (dialog history with all utterances and annotations) into a more suitable and light-weighted input for each service. For example, dialog history may be cut to the last N utterances or only the necessary annotations may be selected.
-
Proxy usage is present throughout various Dream distributions. Such containers are hosted on DeepPavlov servers. Accessing them via proxy allows the users to utilize large models with no GPU load.
-
Components API documentation is designed to provide you with detailed insights into each component’s enpoints